|
人工智能:Meta「分割一切」进入3D时代!
一张普通照片,几秒钟后就能变成可任意旋转的3D模型,Meta的最新AI技术正让计算机视觉变得前所未有的简单和强大。
2025年11月19日,Meta发布了第三代“分割一切”模型SAM 3及其3D版本SAM 3D,标志着计算机视觉领域的一次量子跃迁。
这些模型不仅能通过自然语言描述识别、分割和追踪图像视频中的物体,还能从单张2D图像生成精细的3D模型,即使存在遮挡或复杂背景也能完成高质量重建。
这项技术突破正重塑着从电子商务到野生动物保护等多个领域的传统工作流程。
01 SAM 3:语言驱动的视觉理解革命
SAM 3代表了图像分割领域的范式转变,它突破了传统模型依赖固定标签集的限制,引入了“可提示概念分割”能力。
用户现在可以输入“红色棒球帽”或“条纹猫”等自然语言描述,模型就能自动识别并分割图像或视频中所有符合条件的实例。
在技术架构上,SAM 3建立在共享的Perception Encoder视觉骨干网络上,结合了改进的DETR架构检测器和追踪器模块。
这种设计使得模型在处理含100多个物体的单张图像时仅需30毫秒,在五个并发目标的视频场景中能维持接近实时的性能。
02 三阶段进化:从SAM到SAM 3
Meta的Segment Anything项目经历了三次关键迭代。
初代SAM(2023年4月发布)奠定了项目基础,支持通过点击或框选生成分割掩码,但缺乏语义理解和视频追踪能力。
SAM 2引入了记忆机制,实现了视频中的物体追踪,但仍无法理解文本概念。
SAM 3完成了质的飞跃,将检测、分割和追踪统一到一个模型中,并支持文本和示例提示。
举例来说,在分割野生动物视频中的大象时,SAM需要逐帧手动点击,SAM 2能追踪单个大象但无法识别类别,而SAM 3只需输入“大象”一词就能自动找出并追踪所有大象。
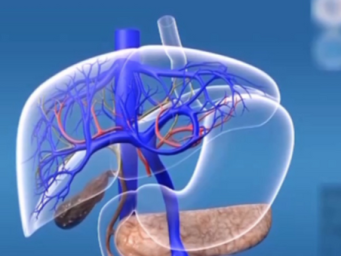
03 SAM 3D:从2D到3D的跨越
SAM 3D系列包含两个专门模型:SAM 3D Objects用于物体和场景重建,SAM 3D Body专注于人体姿势和形状估计。
这些模型实现了从单张2D图像到3D重建的突破,解决了计算机视觉中长期的遮挡难题。
SAM 3D Objects采用两阶段生成流程:
先使用12亿参数的流匹配Transformer预测物体粗糙体素形状和6D布局参数
然后通过纹理与精细化模型合成高保真物体纹理
该模型在人类偏好测试中,其对其他领先模型的胜率至少达到5:1。
SAM 3D Body则采用创新的Momentum Human Rig表示法,将骨骼姿态与身体形状参数显式解耦,即使在异常姿势、遮挡或多人场景下也能准确建模。
04 数据引擎:人机协作的创新
Meta构建了一套创新的数据引擎,将SAM 3、人类标注者和AI模型结合在一起,解决了大规模高质量训练数据标注的难题。
该引擎的工作流程如下:
AI模型(包括SAM 3和基于Llama的图像描述系统)自动挖掘图像和视频,生成描述并创建初始分割掩码
AI标注者基于Llama 3.2v模型验证和修正这些提议,在标注任务上达到或超过人类准确度
人类标注者仅处理最具挑战性的案例
这种人机混合系统使标注速度大幅提升,负提示标注比纯人工快约5倍,正提示标注即使在挑战性领域也快36%。
05 应用场景:从商业到科研
SAM 3和SAM 3D正在多个领域找到实际应用:
商业与创意方面,Meta正在其Facebook Marketplace推出“房间查看”功能,让用户购买前可视化家居装饰品在个人空间的摆放效果。
Instagram的Edits应用将引入SAM 3特效,创作者可将其应用于视频中的特定人物或物体。
科学研究领域,Meta与Conservation X Labs合作构建了SA-FARI数据集,包含超过1万个相机陷阱视频,涵盖100多个物种,每一帧中的每只动物都标注了边界框和分割掩码。
在海洋研究方面,与蒙特雷湾水族馆研究所合作的FathomNet项目为水下图像提供了定制分割掩码和实例分割基准。
机器人技术与医疗健康领域也受益于这些模型的高精度3D感知能力,为自动化和诊断提供新工具。
06 技术局限与未来方向
尽管取得了显著进展,SAM 3仍存在一些局限性。
该模型难以以零样本方式泛化到细粒度的领域外概念,特别是需要专业领域知识的特定术语,如医学图像中的“血小板”。
应用于视频时,SAM 3以类似SAM 2的方式追踪每个物体,推理成本随被追踪物体数量线性增长。
每个物体单独处理,仅利用共享的每帧嵌入,没有物体间的通信。
SAM 3D Objects目前的输出分辨率仍有限,复杂物体的细节可能会缺失,物体布局预测主要专注于单一物体,尚未实现多物体间的物理交互推理。
SAM 3D Body主要设计用于单人体,尚不支持多人互动或人与物体交互的预测。
未来,计算机视觉领域可能会看到2D与3D理解的进一步融合。
Meta已经推出了Segment Anything Playground平台,让普通用户无需技术背景即可体验这些前沿AI模型的能力。
正如NVIDIA开发者技术专家Nader Khalil所言:“这可能是计算机视觉的ChatGPT时刻。强大的分割功能意味着用户只需点击一下就能训练计算机视觉模型。真是太神奇了。”
一句话总结:Meta的SAM 3和SAM 3D不仅突破了图像分割的技术边界,更重新定义了人与视觉内容交互的方式,为AI理解并重建我们的三维世界打开了全新通道。
|
|
 |周边二手车|手机版|标签|xml|txt|新闻魔笔科技XinWen.MoBi - 海量语音新闻!
( 粤ICP备2024355322号-1|
|周边二手车|手机版|标签|xml|txt|新闻魔笔科技XinWen.MoBi - 海量语音新闻!
( 粤ICP备2024355322号-1|